架构-数据库系统3-新技术
数据库安全
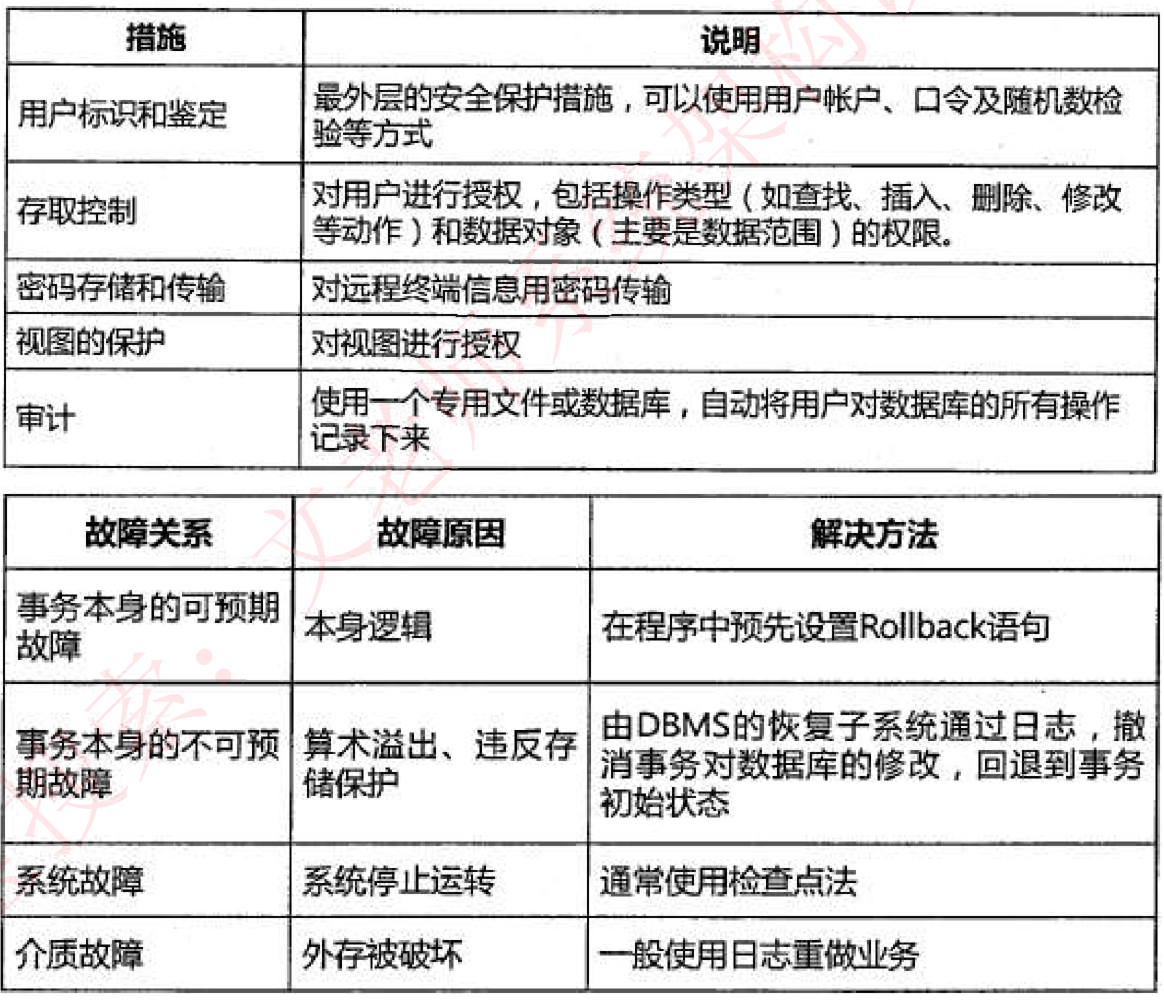
- 静态转存:冷备份。转存期间不允许对数据库进行任何存取、修改操作
- 优点:非常快速的备份方法、容易归档(直接物理复制操作)
- 缺点:只能提供到某一时间点上的恢复,不能做其他工作,不能按表或按用户恢复
- 动态转存:热备份。在转储期间允许对数据库进行存取、修改操作,因此,转储和用户事务可并发执行;
- 优点:可在表空间或数据库文件级备份,数据库仍可使用,可达到秒级恢复;
- 缺点:不能出错,否则后果严重,若热备份不成功,所得结果几乎全部失效。
- 完全备份:备份所有数据
- 差量备份:仅备份上一次完全备份之后变化的数据
- 增量备份:备份上一次备份之后变化的数据
- 日志文件: 在事务处理过程中,DBMS把事务开始、事务结束以及对数据库的插入、删除和修改的每一次操作写入日志文件。一旦发生故障,DBMS的恢复子系统利用日志文件撤销事务对数据库的改变,回退到事务的初始状态
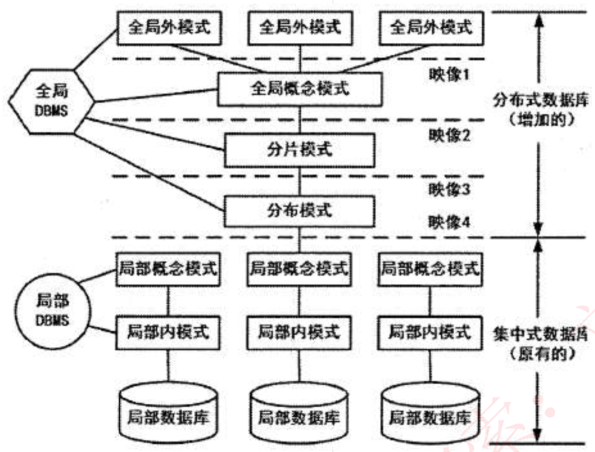
分布式数据库
局部数据库位于不同的物理位置,使用一个全局DBMS将所有局部数据库联网管理,这就是分布式数据库。
分片模式
- 水平分片:将表中水平的记录分别存放在不同的地方
- 垂直分片:将表中垂直的列植分别存放在不同的地方
分布透明性
- 分片透明性:用户和应用程序不需要知道逻辑上访问的表具体是如何分块存储的
- 位置透明性:应用程序不关心数据存户物理位置的改变
- 逻辑透明性:用户或应用程序无需知道局部使用的是哪种数据模型
- 复制透明性:用户或应用程序不关心复制的数据从何而来
二阶段提交(Two-phaseCommit)是指,在计算机网络以及数据库领域内,为了使基于分布式系统架 构下的所有节点在进行事务提交时保持一致性而设计的一种算法(Algorithm)。
通常,二阶段提交也被称为是一种协议(Protocol))。
在分布式系统中,每个节点虽然可以知晓自己的操作时成功或者失败,却无法知道其他节点的操作的成功或失败。
当一个事务跨越多个节点时,为了保持事务的ACID 特性,需要引入一个作为协调者的组件来统一掌控所有节点(称作参与者)的操作结果并最终指示这些节点是否要把操作结果进行真正的提交(比如将更新后的数据写入磁盘等等)。
因此,二阶段提交的算法思路可以概括为:参与者将操作成败通知协调者,再由协调者根据所有参与者的反馈情报决定各参与者是否要提交操作还是中止操作。
所谓的两个阶段是指:
- 第一阶段:准备阶段(表决阶段):事务协调者(事务管理器)给每个参与者(资源管理器)发送Prepare消息,每个参与者要么直接返回失败(如权限验证失败),要么在本地执行事务,写本地的redo和undo日志,但不提交,到 达一种“万事俱备,只欠东风”的状态。
- 第二阶段:提交阶段(执行阶段)。 如果协调者收到了参与者的失败消息或者超时,直接给每个参与者发送回滚(Rollback)消息;否则,发送提交(Commit)消息;参与者根据协调者的指令执行提交或者回滚操作,释放所有事务处理过程中使用的锁资源。(注意:必须在最后阶段释放锁资源)
数据仓库技术
数据仓库是一个面向主题的、集成的、非易失的、且随时间变化的数据集合,用于支持管理决策。
- 面向主题:按照一定的主题域进行组织的。
- 集成的:数据仓库中的数据实在对原有分散的数据库数据抽取、清理的基础上经过系统加工、汇总和整理得到的,必须消除源数据中的不一致性,以保证数据仓库内的信息是关于整个企业的一致的全局信息
- 相对稳定的:数据仓库的数据主要供企业决策分析之用,所涉及的数据操作主要是数据查询,一旦某个数据进入数据仓库以后,一般情况将被长期保留,也就是数据仓库中一般有大量的查询操作,但修改和删除操作很少,通常只需要定期的加载、刷新。
- 反映历史变化:数据仓库中的数据通常包含历史信息,系统记录了企业从过去某一时点(如开始应用数据仓库的时点)到目前各个阶段的额信息,通过这些信息,可以对企业的发展历程和未来趋势做出定量分析和预测
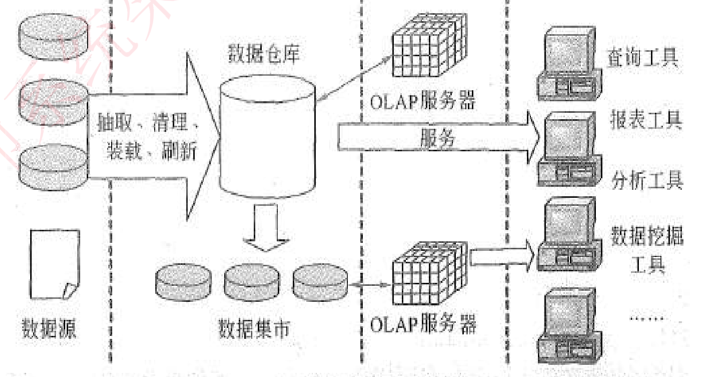
体系机构
包括四个层次
- 数据源:数据仓库系统的基础,是整个系统的数据源泉。
- 数据的存储与管理:整个数据仓库系统的核心。
- OLAP(联机分析处理)服务器:对分析需要的的数据进行有效集成,按多维模型组织,以便进行多角度、多层次的分析,并发现趋势
- 前端工具:包括各种报表工具、查询工具、数据分析工具、数据挖掘工具一级各种基于数据仓库和数据集市的应用开发工具
数据挖掘(英语:Data mining),又译为资料探勘、数据采矿。
它是数据库知识发现(英语: Knowledge-Discovery in Databases,简称:KDD)中的一个步骤。
数据挖掘一般是指从大量的数 据中通过算法搜索隐藏于其中信息的过程。数据挖掘通常与计算机科学有关,并通过统计、在线分 析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上 述目标。
数据挖掘是通过分析每个数据,从大量数据中寻找其规律的技术,主要有数据准备、规律寻找 和规律表示3个步骤。
数据准备是从相关的数据源中选取所需的数据并整合成用于数据挖掘的数据集;
规律寻找是用某种方法将数据集所含的规律找出来;
规律表示是尽可能以用户可理解的方式(如可视化)将找出的规律表示出来。
数据挖掘的任务有关联分析、聚类分析、分类分析、异常分析、特异群组分析和演变分析,等等。
商业智能(BI)
BI系统主要包括数据预处理、建立数据仓库、数据分析和数据展现四个主要阶段。
- 数据预处理:第一步,包括数据的抽取(Extraction)、转换(Transformation)和加载(Load)三个过程(ETL过程)
- 建立数据仓库:处理海量数据的基础
- 数据分析:体现系统智能的关键,采用联机分析处理(OLAP) 和数据挖掘两大技术。
- 联机分析处理:步进进行数据汇聚/聚集,还提供切片、切块、下钻、上卷和旋转等数据分析功能,用户可以方便地对海量数据进行多为分析。
- 数据挖掘:目标则是挖掘数据背后隐藏的知识,通过关联分析、聚类和分类等方法建立分析模型,预测企业未来发展趋势和将要面临的问题;
- 在海量数据和分析手段增多的情况下,数据展现主要保障系统分析结果的可视化
反规范化技术
规范化设计后,数据库设计者希望牺牲部分规范化来提高性能
益处:降低连接操作的需求、降低外码和索引的数目,还可能减少表的数目,能够提高查询效率;
问题:数据的重复存储,浪费磁盘空间;可能出现数据的完整性问题,为了保障数据的一致性,增加了数据维护的复杂性,会降低修改速度;
具体方法:
- 增加冗余列:在多个表中保留相同的列,通过增加数据冗余减少或避免查询时的连接操作;
- 增加派生列:增加由本表或其他表中数据计算生成的列,减少查询时连接操作并避免计算或使用集合函数
- 重新组表:如果许多用户需要查看两个表连接出来的结果数据,则吧这两个表重新组成一个表来减少连接而提高性能。
- 水平分割表:根据一列或多列数据的值,把数据放到多个独立的表中,主要用于表数据规模很大、表中数据相对独立或数据需要存放到多个介质上时使用。
- 垂直分割表:对表进行分割,将主键与部分列放到一个表中,主键与其他列放到另一个表中,在查询时减少I/O次数
大数据
特点:
- 大量化
- 多样化
- 价值密度低
- 快速化
大数据和传统数据的比较如下: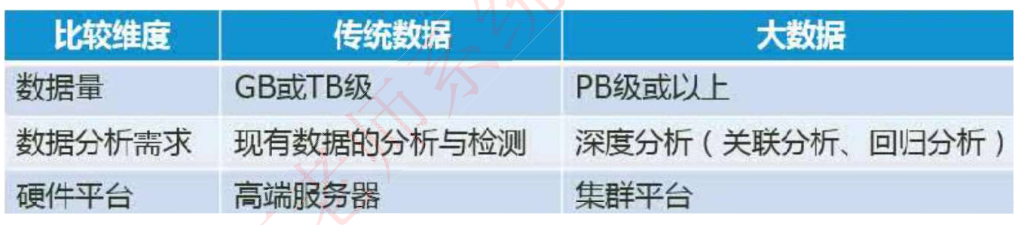
要处理大数据,一般使用集成平台,成为大数据处理系统,特征有:
- 高度可扩展性
- 高性能
- 高度容错
- 支持异构环境
- 较短的分析延迟
- 易用且开放的接口
- 较低成本
- 向下兼容性
SQL语言
略
嵌入式数据库
嵌入式数据库管理系统(Embedded DataBase Management System, EDBMS)就是在嵌入式设 备上使用的DBMS。
由于用到EDBMS的嵌入式系统多是移动信息设备,例如,掌上电脑、PDA、车 载设备等移动通信设备,位置固定的嵌入式设备很少用到,因此,嵌入式数据库也称为移动数据库 或嵌入式移动数据库。
EDBMS的作用主要是解决移动计算环境下数据的管理问题,移动数据库是移动计算环境中的分布式数据库。嵌入式数据库管理系统一般只提供本机服务接口且只为前端应用提供基本的数据支持。