架构-数据库系统2-规范化和并发控制
函数依赖
给定一个X,能唯一确定一个Y,就称X确定Y,或者说Y依赖于X,例如Y=X* X函数
两个规则:
- 完全函数依赖:
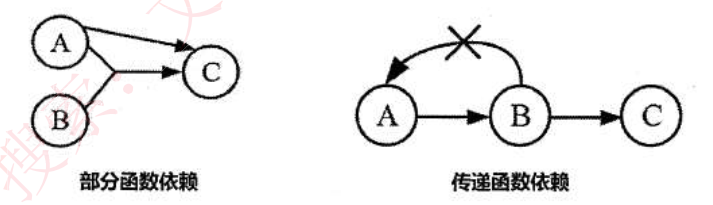
- 部分函数依赖:A可确定C,(A,B)也可确定C,(A,B)中的一部分(即A)可以确定C,成为部分函数依赖
- 传递函数依赖:当A和B不等价时,A可确定B,B可确定C,则A可确定C,是传递函数依赖;若A和B等价,则不存在传递,直接可确定C。
公理系统
设关系模式R<U,F>,U是关系模式R的属性全集,F是关系模式R的一个函数依赖集。
对于R<U,F>来说有以下:
- 自反律:若Y⊆X⊆U,则X→Y为F所逻辑蕴含
- 增广律:若X→Y为F所逻辑蕴含,且Z⊆U,则XZ→YZ为F所逻辑蕴含
- 传递律:若X→Y和Y→Z为F所逻辑蕴含,则X→Z为F所逻辑蕴含
- 合并规律:若X→Y,X→Z,则X→YZ为F所蕴含
- 伪传递律:若X→Y,WY→Z,则XW→Z为F所蕴含
- 分解规律:若X→Y,Z⊆Y,则X→Z为F所蕴含
键与约束
超键:能唯一标识此表的属性的组合
候选键:超键中去掉冗余的属性,剩余的属性就是候选键
主键:任选一个候选键,即可作为主键
外键:其他表中的主键
主属性:候选键内的属性为主属性,其他属于非主属性
实体完整性约束:即主键约束,主键不能为空,也不能重复
参照完整性约束:即外键约束,外键必须是其他表中已经存在的主键的值,或者为空
用户自定义完整性约束:自定义表达式约束,如设定年龄属性的值必须在0到150之间
范式【难】
第一范式1NF
关系中每一个分量必须是一个不可分的数据项。
通俗地说,第一范式就是表中不允许有小表的存在。比如,下表的员工表,就不属于第一范式。
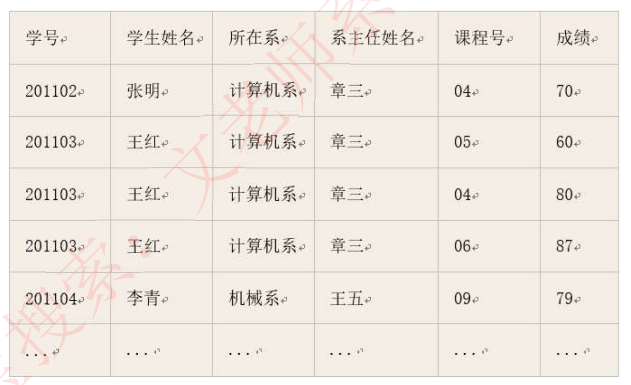
- 实例:用一个单一的关系模式学生来描述学校的教务系统:学生(学好、学生姓名、系号、系主人姓名、课程号、成绩)
- 依赖关系:(学号->学生姓名,学号->系号,系号->系主人姓名,学号->课程号,(学生,课程号)->成绩)
第二范式2NF
【消除部分依赖】
如果关系R属于1NF,且每一个非主属性完全函数依赖于任何一个候选码,则R属于2NF。
通俗地说,2NF就是在1NF的基础上,表中的每一个非主属性不会依赖复合主键中的某一个列。
按照定义,上面的学生表就不满足2NF,因为学号不能完全确定课程号和成绩(每个学生可以选多门课)
将学生表分解为:
学生(学号,学生姓名,系编号,系名,系主任)
选课(学号,课程号,成绩)
每张表均属于2NF
【参考:数据库(第一范式,第二范式,第三范式)_数据库第一范式-CSDN博客】
第三范式3NF
【消除传递依赖】
在满足1NF的基础上,表中不存在非主属性对码的传递依赖
学生关系模型就不属于3NF,因为学生无法直接决定系主任和系名,是由学号->系编号,再由系编号->系主任,系编号->系名,因此存在非主属性对主属性的传递依赖
进一步分解为
学生(学号,学生姓名,系编号)
系(系编号,系名,系主任)
选课(学号,课程号,成绩)
每张表均属于3NF
BC范式
【消除主属性部分传递和传递依赖】
BC模式可以理解为3NF的优化,修正的3NF。
指在第三范式的基础上,进一步消除主属性对于码的部分函数传递和传递依赖
通俗地说,就是在每一种情况下,每一个依赖的左边决定因素都必然包含候选键,如下: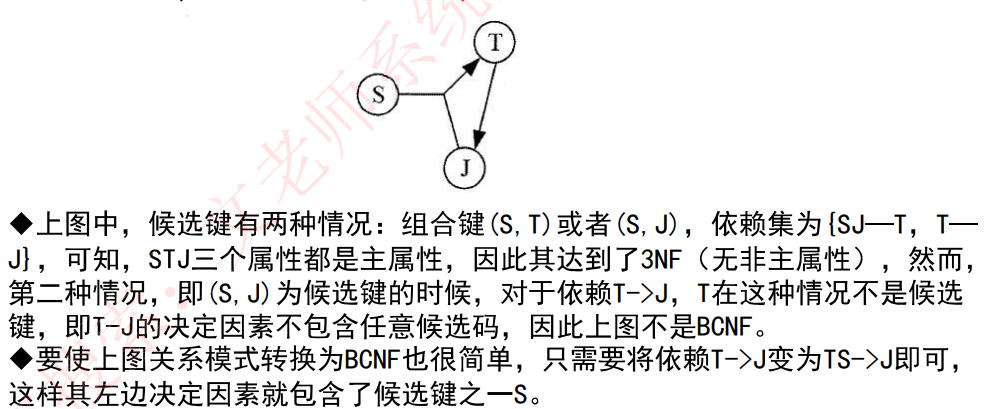 【参考:第一范式、第二范式、第三范式、BCNF范式详解-腾讯云开发者社区-腾讯云】
【参考:第一范式、第二范式、第三范式、BCNF范式详解-腾讯云开发者社区-腾讯云】
【参考:数据库第6章 关系数据理论(第二部分:范式理论 1NF-2NF-3NF)_哔哩哔哩_bilibili】
模式分解【难】
范式之间的转换一般都通过拆分属性,即模式分解,将具有部分函数依赖和传递依赖的属性分离出来,一般以下两种:
- 保持函数依赖分解
对于关系模式R,有依赖集F,若对R进行分解,分解出来的多个关系模式,保持原来的依赖集不变,则为保持函数依赖分解。另外,注意要消除掉冗余依赖(如传递依赖)
实例:R(A,B,C),F(A->B,B->C,A->C),将其分解为两个关系模式R1(A,B)和R2(B,C),此时R1保持依赖A->B,R2包吃依赖B->C,说明分解后的R1和R2包吃函数依赖分解,因为A->C这个函数以来实际是一个冗余依赖,可以由前两个传递得到,所以需不要管。 - 无损分解:分解后的关系模式能够还原出原关系模式。
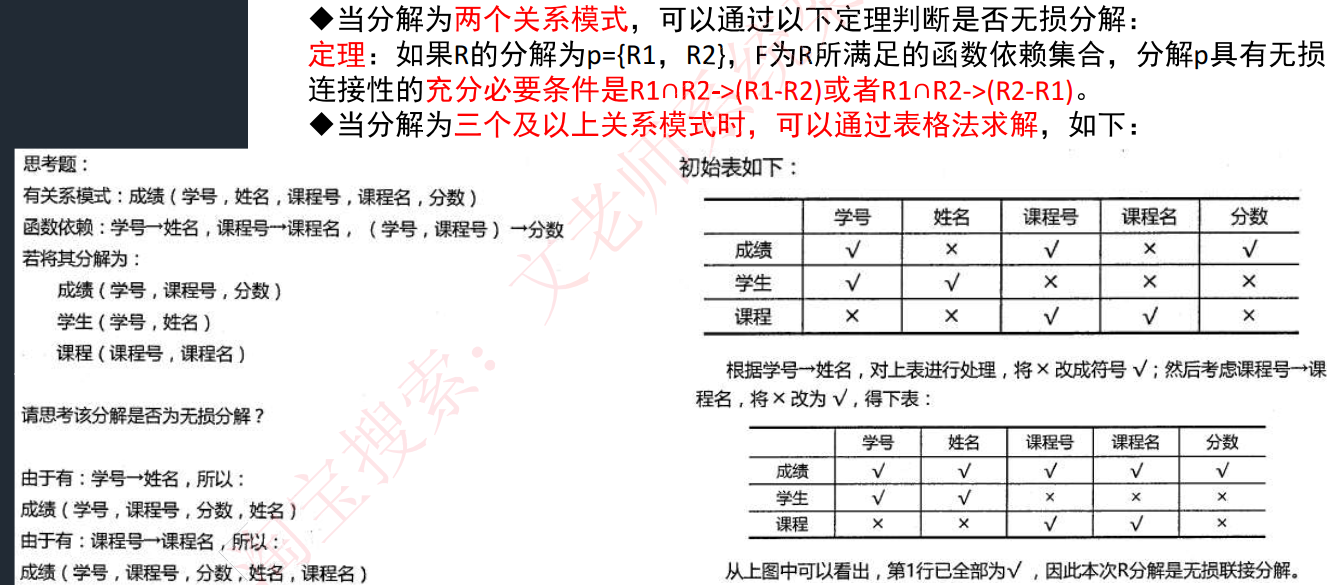
【?需要学习视频】
并发控制
- 事务:由一系列操作组成,这些操作,要么全做,要么全不做,拥有四种特性:
- (操作)原子性:要么全做,要么全不做
- (数据)一致性:事务发生后数据是一致的,例如银行转账,不会存在A账户转出,B账户没收到的情况
- (执行)隔离性:任一事务的更新操作知道其成功提交的整个过程对其他事物都是不可见的,不同事务之间是隔离的,互不干涉
- (改变)持续性:事务操作的结果是持续性的
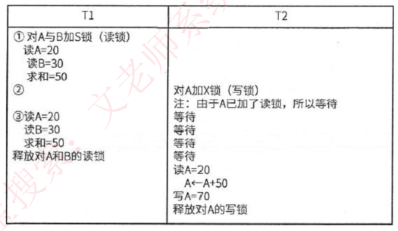
事务是并发控制的前提条件,并发控制就是控制不同的事务并发执行,提高系统效率,但是并发控制中存在下面三个问题:
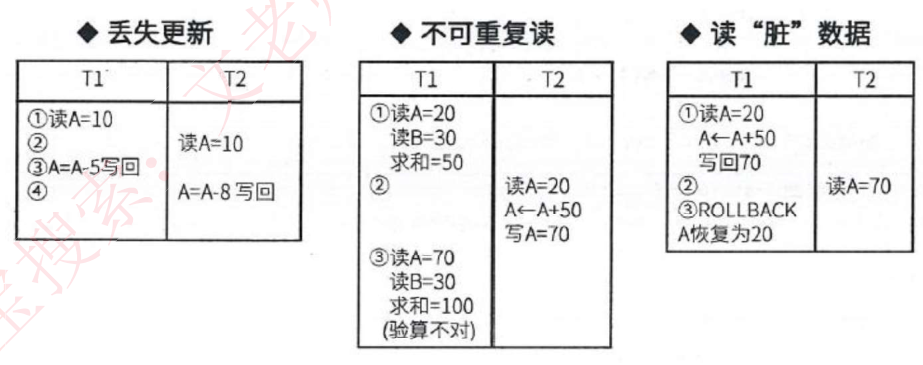
- 丢失更新:事务1对数据A进行了修改并写回,事务2也对A进行了修改并写回,此时事务2写回的数据会覆盖事务1写回的数据,就丢失了事务1对A的更新。即数据A的更新会被覆盖
- 不可重复读:事务2读A,而后事务1对数据A进行了修改并写回,此时若事务2再读A,发现数据不对。即一个事务重复读A两次,会发现数据A有误。
- 读脏数据:事务1对数据A进行了修改后,事务2读数据A,而后事务1回滚,数据A恢复了原来的值,那么事务2对数据A的事是无效的,读到了脏数据
封锁协议
- X锁是排它锁(写锁)。若事务T对数据对象A加上X锁,则只允许T读取和修改A,其他事务都不能再对A加任何类型的锁,直到T释放A上的锁
- S锁是共享锁(读锁)。若事务T对数据对象A加上S锁,则只允许T读取A,但是不能修改A,其他事务只能在对A加S锁(也即能读不能修改),直到T释放A上的S锁。
共分为三级封锁协议,如下:
- 一级封锁协议:事务在修改数据R之前必须对其加X锁,直到事务结束才释放。可解决丢失更新问题。
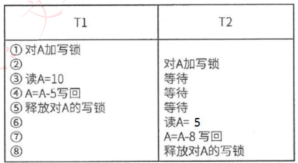
- 二级封锁协议:一级封锁协议的基础上加上事务T在读数据R之前必须对其加S锁,读完后即可释放S锁。可解决丢失更新、读脏数据问题
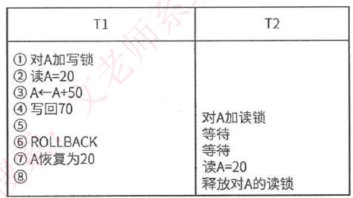
- 三级封锁协议:一级封锁协议加上事务T在读取数据R之前必须现对其加S锁,直到事务结束才释放。可解决丢失更新、读脏数据、数据重复读问题。